Despite numerous proposals for its creation, the semantic web has yet to achieve widespread adoption. Recently, some researchers have argued that participation in the semantic web is too difficult for ``ordinary'' people, limiting its growth and popularity.
In response, this paper introduces MANGROVE, a system whose goal is to evolve a portion of the semantic web from the enormous volume of facts already available in HTML documents. MANGROVE seeks to emulate three key conditions that contributed to the explosive growth of the web: instant gratification for authors, robustness of services to malformed and malicious information, and ease of authoring. In the HTML world, a newly authored page is immediately accessible through a browser; we mimic this feature in MANGROVE by making semantic content instantly available to services that consume the content and yield immediate, tangible benefit to authors.
We have designed and implemented a MANGROVE prototype, built several semantic services for the system, and deployed those services in our department. This paper describes MANGROVE's goals, introduces the system architecture, and explains how this architecture achieves our goals. Overall, MANGROVE demonstrates a concrete path for enabling and enticing non-technical people to enter the semantic web.
Semantic Web, instant gratification, services, adoption.
Today's web was built to present documents for humans to view, rather than to provide data for software-based processing and querying. In response, numerous proposals for creating a semantic web have been made in recent years, yet adoption of the semantic web is far from widespread.
Several researchers have recently questioned whether participation in the semantic web is too difficult for ``ordinary'' people [2,1]. Indeed, a key barrier to the growth of the semantic web is the need to structure data: technical sophistication and substantial effort are required whether one is creating a database schema or authoring an ontology. The database and knowledge representation communities have long ago recognized this challenge as a barrier to the widespread adoption of their powerful technologies. The semantic web exacerbates this problem, as the vision calls for large-scale and decentralized authoring of structured data. As a result, the creation of the semantic web is sometimes viewed as a discontinuous divergence from today's web-authoring practices -- technically sophisticated people will use complex tools to create new ontologies and services.
While the discontinuous approach will certainly yield many useful semantic web services, this paper is concerned with the evolutionary approach: a significant part of the semantic web can evolve naturally and gradually as non-technical people structure their existing HTML content. In fact, the two approaches are not competing but complementary. Each focuses on a different user base, data sources, and services. Furthermore, each approach gives rise to a somewhat different set of challenges. A key question for the evolutionary approach is how do we entice people to structure their data? Structuring must be made easy, incremental, and rewarding.
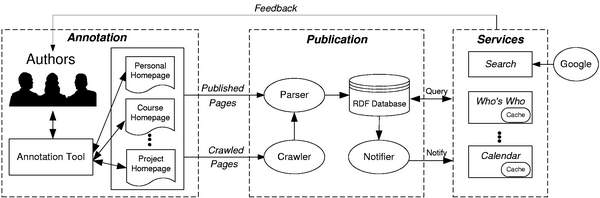
This paper presents the architecture of MANGROVE, a semantic web system that embodies an evolutionary approach to semantic content creation and processing. In particular, MANGROVE seeks to emulate three key conditions that contributed to the explosive growth of the web. The first condition is ease of authoring: MANGROVE provides a graphical web-page annotation tool that enables users to easily and incrementally annotate existing HTML content. The second condition is instant gratification: in the HTML world, a newly authored page is immediately accessible through a browser; we mimic this feature in MANGROVE by making annotated content instantly available to services. We posit that semantic annotation will be motivated by services that consume the annotations and result in immediate, tangible benefit to authors. MANGROVE provides several such services and the infrastructure to create additional ones over time. The third condition is robustness: when authoring an HTML page, authors are not forced to consider the contents of other, pre-existing pages. Similarly, MANGROVE does not require authors of semantic content to obey integrity constraints, such as data uniqueness or consistency. Data cleaning is deferred to the services that consume the data.
As one example of the MANGROVE approach, consider the homepage of an individual, a university course, or a small organization. Such pages contain numerous facts including contact information, locations, schedules, publications, and relationships to other information. If users were enabled and motivated to annotate these pages, then the very same pages and text could be used to support both the semantic web and standard HTML-based browsing and searching. For example, we can easily produce a departmental phone list by extracting phone numbers from annotated home pages for the faculty and students in our department. Similarly, we have created a departmental calendar that draws on annotated information found on existing web pages, which describe courses, seminars, and other events (See http://www.cs.washington.edu/research/semweb for these and other live services). Both services instantly consume annotated facts and help motivate people to participate in the semantic web.
|
| Figure 1: The MANGROVE architecture and sample services |
Figure 1 shows the architecture of MANGROVE organized around the following three phases of operation:
These three phases are overlapping and iterative. For instance, after annotation, publication, and service execution, an author may refine her documents to add additional annotations or to improve data usage by the service. In addition, we believe that annotation will be an incremental process starting with ``light'' annotation of pages and gradually increasing in scope and sophistication as more services are developed to consume an increasing number of annotations. Supporting this complete life-cycle of content creation and consumption is important to fueling the semantic web development process.
MANGROVE as described here has been fully implemented and deployed in our department, complete with a simple schema, the annotation tool, and several instant gratification services. See [3] for a more complete description of the system and our experiences with MANGROVE.
MANGROVE is designed to support the goals listed towards the end of Section 1. First, MANGROVE supports ease of authoring by providing a simple graphical annotation tool, deferring integrity constraints to the application, and permitting authors to annotate HTML lightly and incrementally. Next, MANGROVE supports instant gratification with a loop that takes freshly published semantic content through the parser, to the database, through the notifier, to MANGROVE services, and then back to the user through the service feedback mechanism mentioned above. Finally, MANGROVE supports robustness with its service feedback mechanism, by associating a source URL with every fact in the database, and by providing a service construction template, which assists services in cleaning and interpreting the data based on these URLs.
A fundamental difference between MANGROVE and traditional data management applications is that authors who enter data may not be aware of which services consume their data and what is required in order for their data to be well formed. Hence, an author may annotate data and publish it, but then fail to find the desired event in the calendar (perhaps because the calendar did not understand the dates specified). The challenge is to create an environment where a novice user can easily understand and rectify this situation.
To address this problem, we provide the service feedback mechanism that accepts a URL as input. Services registered with the notifier then process all annotated data at that URL and output information about problems encountered (e.g., a date was ambiguous or missing) and/or about successful processing (e.g., a link to the newly added calendar event).1 As a convenience, we invoke the service feedback mechanism whenever authors publish new data. Thus, this mechanism supports both robustness (by helping authors to produce well-formed data) and instant gratification (by making it easier for authors to find the tangible output resulting from their new semantic data). Furthermore, the mechanism enables authors to receive serendipitous feedback from services previously unknown to the author, thus creating a discovery mechanism for potentially relevant semantic services.
Our goal in designing MANGROVE and in deploying it locally has been to test our design on today's HTML web against the requirements of ordinary users. MANGROVE and the services it enables are in everyday use in our department. Clearly, additional deployments in different universities, organizations, and countries are necessary to further refine and validate MANGROVE's design. New instant gratification services are necessary to drive further adoption, and a broad set of measurements is essential to test the usability and scalability of the system. Finally, we plan to incorporate MANGROVE as part of a peer-data management system to achieve web scale.